Object Storage is launching soon
A huge shift in software architecture happened with the industry adoption of Amazon S3 and “object storage” APIs. Building applications that take advantage of this high-latency, but highly-durable blob-based storage has become the norm, and blob storage underpins basically every part of the modern Cloud and software stack.
When we set out building Worktree Cloud, we knew that our first real challenge would be storage. Worktree itself uses object storage extensively for all sorts of things, and up until recently it was all still on Amazon S3.
We needed an alternative.
We were faced with a choice: solve the problem for ourselves quickly by running something off-the-shelf like Ceph or Minio, or start from scratch and build our own storage platform. Naturally, we took the latter; we have a lot of ambitions beyond basic object storage, and if we really want to compete with Big Tech, we need a platform, not a product.
By building our own storage platform, we can build tightly-integrated features with the rest of our Cloud, and can build in custom features that would be much more difficult to shoehorn into an off-the-shelf product – think: automatic tiering, multi-region replication, intelligent load balancing, encryption…
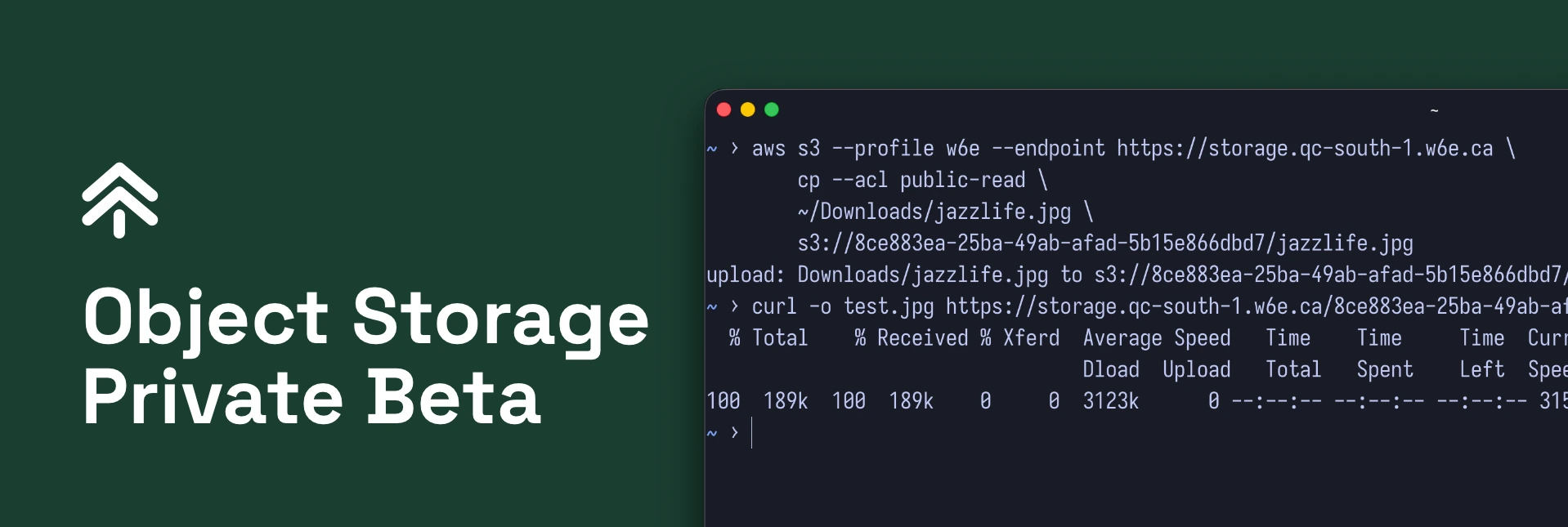
But we don’t want to start entirely from scratch. If we invent a new, proprietary API for object storage, no one will care or want to use it. Even Microsoft has struggled to penetrate the market with Azure Blob Storage API support. The fact is, if we want anyone to use our object storage, it needs to work with existing S3 clients. So we reverse-engineered the S3 API.
It took a lot of work and a few months, but as of the time of writing Worktree now fully runs on our own object storage platform. The migration used standard tools like rclone, and the switch-over was a zero-downtime config change that swapped one S3 configuration for another.
We plan to publish a litany of technical content about how object storage works under the hood and the architectural decisions that went into it. But, for now, in short, we built it the same way the hyperscalers did: erasure coding, consistent hashing, and a lot of hard drives.
Our crazy idea of “let’s reinvent S3 from scratch” worked out. As we shake out the bugs and scale our infrastructure capacity, we’ll start opening up a private beta for those on the waiting list. We’re so excited to see all this work come to fruition, and can’t wait to see more production workloads storing data on Worktree Cloud.
You can sign up for the waiting list on the Worktree Cloud Object Storage page.
As always, reach out to us on Discord, email, or any of our social media profiles if you have questions.
Let’s get back to building.